Intermittent
TOOLKIT Python, Google Colab, Hugging Face

StyleGANs
Image Generation
Light and shadow
Concept
How can we capture the intermittent phases between light and darkness through making an image generation model?

StyleGANs
StyleGAN is a Generative Adversarial Network which is used to train an image generation model to generate images. It has two main parts:
- Generator: Creates images from random noise, starting with blurry low-resolution images and progressively adding detail until they look realistic. It does this by learning the underlying patterns and structures present in a dataset of images during training.
- Discriminator: Acts as a critic, learning to tell real images from fake ones, which pushes the generator to improve. It learns to classify images as real or fake by comparing them to the images it has seen during training.

These two parts compete against each other during training—the generator tries to fool the discriminator, while the discriminator gets better at spotting fakes. This competition results in increasingly realistic images.

How I'm using StyleGAN: Instead of just using the final polished images, I'm capturing the in-between stages of training—the partially formed, imperfect images that emerge as the model learns. These transitional visuals became the foundation for my poster designs, perfectly reflecting the project's theme of exploring the space between light and darkness.



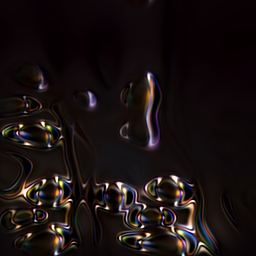



Image Generation
The first step was curating a dataset of images. I wanted to create monochrome and duochrome visuals based on light and dark places, so I searched through my archive for images that fit the theme. Next, I ran Python code on a Google Colab notebook to train the model. Generating different iterations of images—called seeds—takes a long time. I completed about ten rounds of generation.
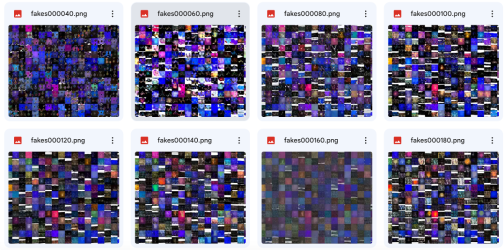
Text Generation
For the text elements on the poster, I sourced quotes from "All the Light We Cannot See" by Anthony Doerr. I was watching the show adaptation at the time and found it captivating. I used spaCy in my Python code to identify different parts of speech within the text, then constructed custom phrases from them. I also used Hugging Face's Mistral-7B-v0.1 model to generate text based on specific prompts.

Credits
-
Text SourceAll the Light We Cannot See by Anthony Doerr
-
Images sourceAll images taken by me